前言
现在算是终于有空来写这篇文章了,由于考研的问题一直没有时间来补这篇文章
- 该问题最早提出是在9月份开发新院统战项目时提出的,也就是我刚刚搭完第一版后端框架,其中持久层使用的框架是mybatis plus,缓存使用的是sprinboot缓存注解+redis,其中将缓存注解加在service层。
- 当时在使用mybatis plus并以注解开发时,由于过度使用@One与@Many注解进行属性的封装,例如:
@Select("SELECT id,dept_id,username,nick_name,gender,phone,email,avatar_path,password," +
"is_admin,enabled,create_by,update_by,pwd_reset_time,create_time,update_time" +
" FROM sys_user u WHERE u.id = #{id} AND is_deleted=0")
@Results({
@Result(column = "id", property = "id"),
@Result(column = "dept_id", property = "deptId"),
@Result(column = "dept_id", property = "dept",
one = @One(select = "marchsoft.modules.system.mapper.DeptMapper.selectById",
fetchType = FetchType.EAGER)),
@Result(column = "id", property = "roles",
many = @Many(select = "marchsoft.modules.system.mapper.RoleMapper.findWithMenuByUserId",
fetchType = FetchType.EAGER)),
@Result(column = "id", property = "jobs",
many = @Many(select = "marchsoft.modules.system.mapper.JobMapper.findByUserId",
fetchType = FetchType.EAGER))
})
UserBO findUserDetailById(Long id);但是没有考虑到一句@One就是一条新的sql,一句@Many就又是n条sql,在没有缓存的情况下效率是非常低的,这就牵扯到之后的不断探究与讨论了。
探究
在之后的不断讨论与探究中,主要从以下几个方面就行抉择:
选择 springboot + redis 缓存
- 保持与原先与eladmin相同的缓存方法,通过@CacheConfig与@Cacheable将缓存加在service中,仅仅只缓存以id或某字段为主键的记录(类似数据库中一条一条的数据),不缓存分页查询或自己封装后的数据。同时自己对哪些数据加了缓存,还要需要自己手动去维护。
@Service
@AllArgsConstructor
@CacheConfig(cacheNames = "role")
public class RoleServiceImpl implements IRoleService {
private final RoleMapper roleMapper;
@Override
@Cacheable(key = "'id:' + #p0")
public Role getOneById(Serializable id) {
return this.roleMapper.selectById(id);
}
@Override
public List<Role> getRolesById(Serializable id) {
return roleMapper.getRoleByUser(id);
}
}- 这样加缓存的好处是缓存键值清晰,便于存取和删除,还可以建立缓存的命名空间,使缓存结构清晰易于管理。
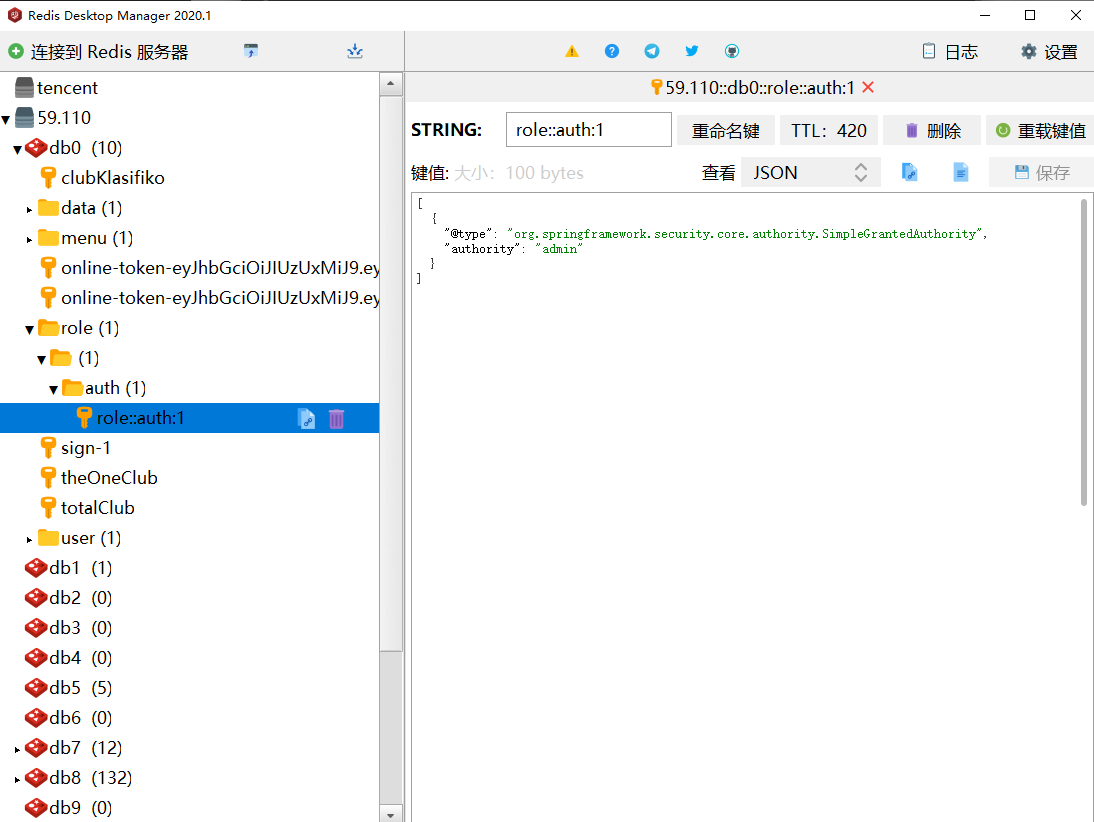
springboot缓存方式与@One、@Many之间的矛盾
- 上述的缓存方式虽然很理想,但是会导致@One与@Many的查询无法正常走缓存,首先是@One与@Many方法只能调用mapper层的查询方法(调用service层会报错),这就必须要求@CacheConfig与@Cacheable需要加在mapper层的接口方法上(springboot不建议将缓存加在接口方法上)
其次即使将缓存注解加在了mapper层上,@One与@Many中所调用的查询方法仍然无法走缓存 - 原因是@One与@Many在实现原理上并不是直接通过反射真正的去调用所指定的方法,而是与当前目标方法结合在了一起。
到这里就可以发现第一个令人头疼的地方,就是如果使用原生@One与@Many进行开发时,是必定走不了springboot的缓存方式,这里就需要考虑第二种缓存方式了。
mybatis的二级缓存
- 能使原生@One与@Many以及其所在的方法走缓存的唯一方式就是使用mybatis的二级缓存,当然mybatis自己实现的缓存是存在项目本身的内存中,这当然不符合我们的要求,这里是结合redis实现ibatis的cache接口来开启二级缓存。
@CacheNamespace(implementation = MybatisRedisCache.class, eviction = MybatisRedisCache.class)
@Component
public interface UserMapper extends BasicMapper<User> {}-
但其实使用了mybatis的二级缓存之后,看起来貌似解决了@One与@Many不走缓存的问题,但是却又带了许多其他的小问题:
mybatis plus的分页插件有的时候显示总条数与总页数为0,但结果数据还有 -
该问题网上也有提到过,但是唯一的建议就是关闭mybatis的二级缓存,说是二级缓存与分页插件之间有冲突。
缓存没有命名空间,键名是一串随机数字,不易管理与维护 -
使用了二级缓存结合redis之后,redis中的缓存就变成了这个样子:
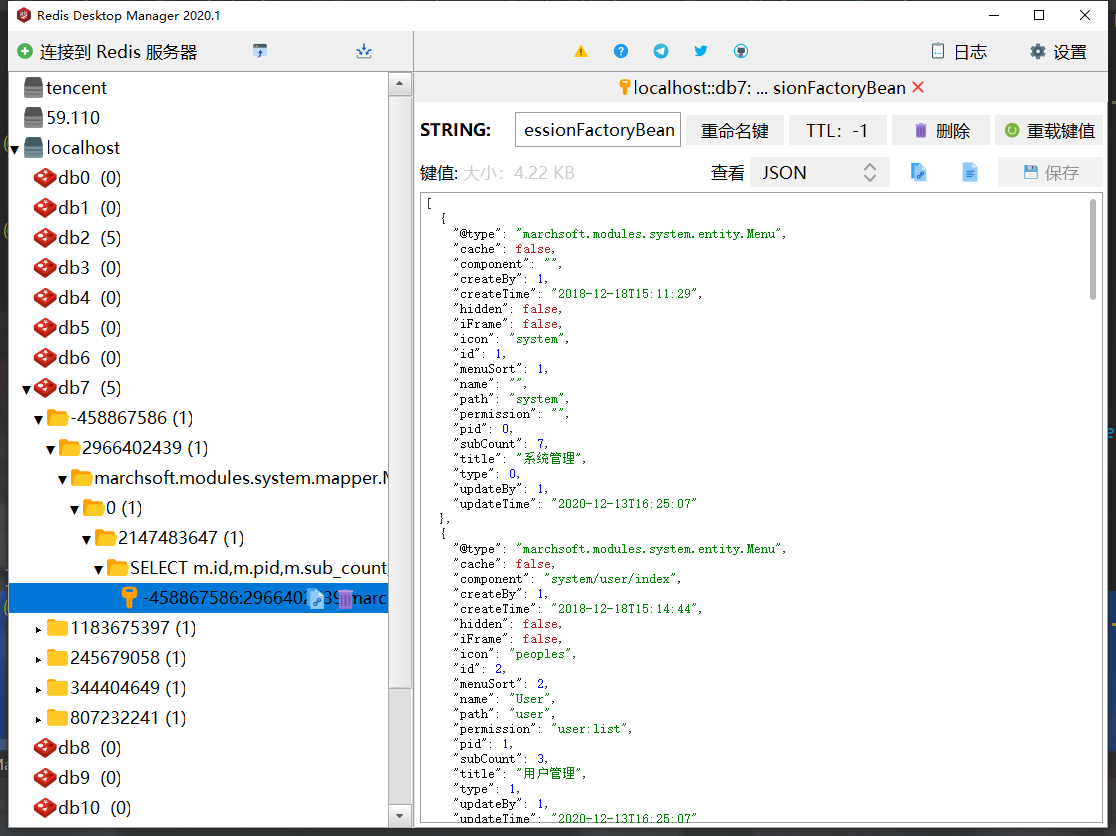
-
这相较于原先使用springboot + redis缓存的结果乱了很多,而且根本不知道哪个key到底存了什么。
二级缓存的自动维护会删除该mapper下的所有缓存 -
手动通过redis实现ibatis的cache接口有以下几个需要实现的方法:
public class MyRedisCache implements Cache {
//当前放入缓存的mapper的namespace
private final String id;
//必须要有这个构造方法
public MyRedisCache(String id){
this.id = id;
}
//返回cache唯一标识————即namespace
@Override
public String getId() {
return this.id;
}
@Override
public void putObject(Object key, Object value) {
System.out.println("key : " + key.toString() + "--- value : " + value.toString());
//使用redishash类型作为缓存存储模型 key hashkey value
getRedisTemplate().opsForHash().put(id.toString(), key.toString(), value);
}
@Override
public Object getObject(Object key) {
return getRedisTemplate().opsForHash().get(id.toString(), key.toString());
}
@Override
public Object removeObject(Object o) {
return null;
}
//清空整个id的所有key缓存,mybatis默认走这个
@Override
public void clear() {
getRedisTemplate().delete(id.toString());
}
@Override
public int getSize() {
return getRedisTemplate().opsForHash().size(id).intValue();
}
private RedisTemplate getRedisTemplate(){
RedisTemplate redisTemplate = SpringContextHolder.getBean("redisTemplate");
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setHashKeySerializer(new StringRedisSerializer());
return redisTemplate;
}
}- 其中mybatis二级缓存存储一个记录需要有id与key来标识,其中id就是所在的mapper,key就是键名
mybatis的二级缓存在遇到删改方法时会自动清理缓存,走的是cache接口中的clear方法,会将该id下(就是该mapper)的所有缓存全部删除,而不是根据具体的某个key去删除缓存。 - 相较于之前springboot + redis的手动维护缓存,是你删除和更新了某条数据,才仅仅将这条数据的缓存删除,而mybatis二级缓存这样直接清除力度过大,如果说为什么不清单个,原因应该有以下两个:
- removeObject(Object o)还未实现,这是mybatis自身待完善的地方
- 由于二级缓存存储时键名是随机的,维护难度过大。
- 上述就是使用二级缓存时又带来的困扰
不使用@One、@Many注解,手动封装结果,调用service层方法走springboot缓存
- 这个是讨论的最后一种方式,就是不使用@One、@Many注解直接在mapper层进行数据封装,而是第一次查到主体数据,在业务层再次调用其他service层的方法对剩余属性进行封装,这样调用的其他方法就可以走springboot的缓存方式了,这个方案是一个折中的方案,虽然没有@One、@Many的方便开发效率,但是至少维持了适中的执行效率和便于维护的缓存存储结构与方式。
最终方案
由于博主本人需要考研的原因,11月之后不再参与框架的更新迭代,缓存的问题也一直遗留了下来,目前第二版框架SMPE已经基本成型,最大的遗留问题就是缓存问题了
2021年1月10日博主再次参与框架的更新迭代中,并且再次接手框架缓存的解决方案
2021年1月10日晚与同学星星讨论后,定下尝试解决方案——重新实现@One与@Many注解,使新注解可以调用service层/mapper层的方法,从而走springboot缓存,其目标为既可以到达原生@One与@Many的开发效率,又可以使用最理想的缓存存储方案!
- 幸运的是,我们的初步想法是可行的,通过1天的努力与尝试,运用springboot切面编程的思想与java反射原理开发了新的注解——@Query与@Queries,通过新注解@Query与@Queries实现了原先@One和@Many的效果,最重要的调用的方法是通过反射去真真正正调用了一条方法,因此成功走了springboot的缓存。
注解源码展示 - 首先是 @Query
// 重新实现 @One、@Many注解,关联查询注解,用于mapper层查询方法上,仅需关联查询一个属性时,可以直接使用@Query
// 如果需要使用多个@Query,请先使用@Queries套在外层(类似 @Results)参数、作用基本和原@One保持一致
// 既可以用于一对一也可以一对多
//
// @author Wangmingcan
// Date: 2021/01/12 09:35
//
@Documented
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
@Repeatable(Queries.class)
public @interface Query {
/** 被关联的列,一般为id,请保证和实体类中属性名称一致,驼峰下划线都可以
* 如关联的列为dept_id,填deptId和dept_id都可以*/
String column() default "";
/** 关联的属性 ,和实体类中需要封装的属性名称保持一致*/
String property() default "";
/** 执行的查询方法,建议填写mapper层的全限定方法名 ,方法返回值必须和property类型一致*/
String select() default "";
}- 其次是 @Queries
//
// 多个关联查询注解,用于mapper层查询方法上
// 使用方法类比 @Results ,里面套多个 @Query
// Queries({
// @ Query(),@Query(),...
// })
//
// Date: 2021/01/12 09:35
//
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.METHOD})
public @interface Queries {
Query[] value() default {};
}- 最后是注解的具体实现
// Query注解具体实现
//
// Date: 2021/01/12 09:35
//
@Aspect
@Component
public class QueryAspect {
/** Query注解配置切面织入点 */
@Pointcut("@annotation(marchsoft.annotation.Query)")
public void queryPointcut() {}
/** Queries注解配置切面织入点 */
@Pointcut("@annotation(marchsoft.annotation.Queries)")
public void queriesPointcut() {}
//
// Date : 2021-01-12 09:50
// @param joinPoint 切入点
// @param result 目标方法返回值
// 方法执行后切入并修改目标方法返回值
//
@AfterReturning(value = "queryPointcut()", returning = "result")
public void queryAround(JoinPoint joinPoint, Object result) {
MethodSignature signature = (MethodSignature) joinPoint.getSignature();
Method signatureMethod = signature.getMethod();
Query query = signatureMethod.getAnnotation(Query.class);
//如果目标方法返回类型为 Collection的实现类,如List,则通过迭代器遍历
//如果目标方法返回类型为 IPage,则先获取getRecords()的List,再通过迭代器遍历
if (result instanceof Collection || result instanceof IPage) {
Iterator iter;
if (result instanceof Collection) {
iter = ((Collection) result).iterator();
}else {
iter = ((IPage) result).getRecords().iterator();
}
while(iter.hasNext()){
execute(query, iter.next());
}
}else { //如果目标方法返回类型即为实体类
execute(query, result);
}
}
@AfterReturning(value = "queriesPointcut()", returning = "result")
public void queriesAround(JoinPoint joinPoint, Object result) {
MethodSignature signature = (MethodSignature) joinPoint.getSignature();
Method signatureMethod = signature.getMethod();
Queries queries = signatureMethod.getAnnotation(Queries.class);
if (result instanceof Collection || result instanceof IPage) {
Iterator iter;
if (result instanceof Collection) {
iter = ((Collection) result).iterator();
}else {
iter = ((IPage) result).getRecords().iterator();
}
while(iter.hasNext()){
Object o = iter.next();
//针对每个实体处理多个@query
for (Query query : queries.value()) {
execute(query, o);
}
}
}else {
for (Query query : queries.value()) {
execute(query, result);
}
}
}
//
// Date : 2021-01-11 15:38
// @param query 注解query
// @param result 目标方法返回值
//
private void execute(Query query, Object result) {
//获取需要被赋值的属性
String property = query.property();
//获取需要执行的方法
String select = query.select();
//获取关联的列,并转驼峰
String column = StringUtils.toCamelCase(query.column());
//关联属性的类型(也为select的参数类型)
Class<?> columnType;
//关联列的值
Serializable columnValue;
//select方法返回值类型
Class<?> selectMethodReturnType;
//select方法返回结果
Object selectResult;
try {
//目标方法返回值类型class
Class<?> resultClass = result.getClass();
//通过反射获取get方法并调用来获取关联列的值
try {
Method getMethod = resultClass.getMethod("get" +
column.substring(0, 1).toUpperCase() + column.substring(1));
columnValue = (Serializable) getMethod.invoke(result);
columnType = getMethod.getReturnType();
}catch (NoSuchMethodException get) {
throw new BadRequestException("找不到get方法 : " + get.getMessage() +
",请检查column参数" + column + "是否填写正确");
}
//通过反射获取该select方法所在的类
int pointIndex = select.lastIndexOf(".");
Class<?> selectMethodClass = Class.forName(select.substring(0, pointIndex));
//通过反射获取需要调用的select方法
try{
Method selectMethod = selectMethodClass.getMethod(select.substring(pointIndex+1), columnType);
//调用并获取select方法的结果
selectResult = selectMethod.invoke(SpringContextHolder.getBean(selectMethodClass),
columnValue);
selectMethodReturnType = selectMethod.getReturnType();
}catch (NoSuchMethodException selectExc) {
throw new BadRequestException("找不到select方法 : " + selectExc.getMessage() +
",请检查select方法的名称和参数类型");
}
//通过反射获取set方法并调用来完成赋值
try{
Method setMethod = resultClass.getMethod("set" +
property.substring(0, 1).toUpperCase() + property.substring(1), selectMethodReturnType);
setMethod.invoke(result, selectResult);
}catch (NoSuchMethodException set) {
throw new BadRequestException("找不到set方法 : " + set.getMessage() +
",请检查" + property + "的类型与方法" + select + "的返回值是否一致");
}
}catch (Exception e) {
e.printStackTrace();
}
}
}- 其中字符串转驼峰的toCamelCase方法来自StringUtils工具类,获取调用select中需要传入的service/mapper实例通过SpringContextHolder来获取。
- 其中对IPage的判断是使用了mybatis plus的分页插件的情况下需要考虑的一种情况,如果没有使用mybatis plus或者是其分页插件,把对IPage的判断去除即可。
@Select("SELECT id,dept_id,username,nick_name,gender,phone,email,avatar_path,password," +
"is_admin,enabled,create_by,update_by,pwd_reset_time,create_time,update_time" +
" FROM sys_user u WHERE u.id = #{id} AND is_deleted=0")
@Results({
@Result(column = "id", property = "id"),
@Result(column = "dept_id", property = "deptId"),
})
@Queries({
@Query(column = "id", property = "roles",
select = "marchsoft.modules.system.mapper.RoleMapper.findWithMenuByUserId"),
@Query(column = "id", property = "jobs",
select = "marchsoft.modules.system.mapper.JobMapper.findByUserId"),
@Query(column = "dept_id", property = "dept",
select = "marchsoft.modules.system.mapper.DeptMapper.selectById")
})
UserBO findUserDetailById(Long id);- 加缓存方式与原先一致:
@Component
@CacheConfig(cacheNames = "dept")
public interface DeptMapper extends BasicMapper<Dept> {
@Cacheable(key = "'id:' + #p0")
Dept selectById(Long id);
}- 无论返回结果是UserBO,还是List
,还是Set ,还是IPage ,最终的查询结果都是和原先使用@One与@Many的时候是一致的,而且缓存存储结构与以前也是一样的:
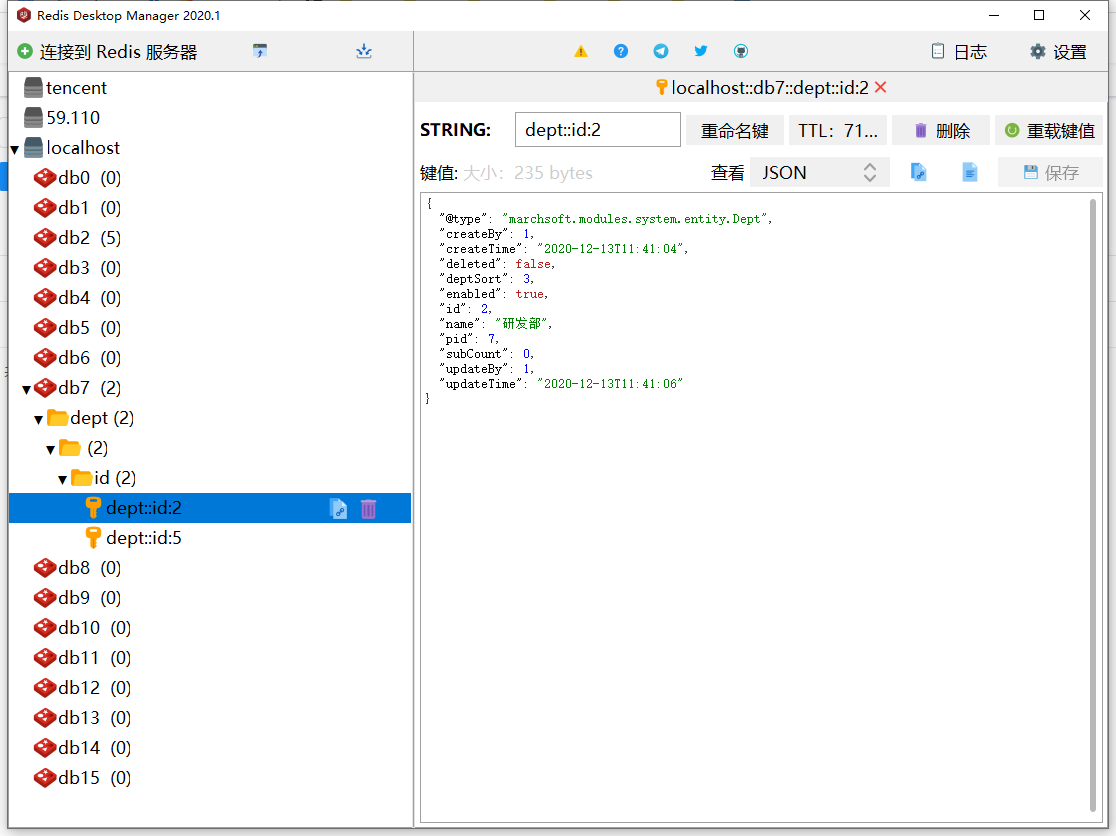
总结
- 上述就是目前想到并实现的最佳缓存解决方案,即具备了原先@One、@Many注解的开发效率,又保留了缓存的存储结构,虽然仍然需要手动维护缓存,但和学长一致认为这是合理的,谁对哪一个方法加了缓存,就有义务自己去维护他,况且难度也比较低。
- 但上述注解仅仅是实现了原有@One、@Many的最基本的查询封装功能,类似于@Many的fetchType = FetchType.EAGER/LEAZY等功能还需后续不断继续完善。
- 自此,长达数月的缓存大问题拉下帷幕。
缓存的添加与维护
- springboot缓存注解的复习————SpringBoot2.0的@Cacheable(Redis)缓存失效时间解决方案
- 根据上述所说可知,我们是把缓存注解加在了mapper层,所以首先我要说明同时在service层和mapper加缓存时的问题:
service与mapper加相同的命名空间时,即CacheConfig(cacheNames = "xx")相同,此时会将service和mapper缓存合并,但是如果出现service和mapper中缓存的键名相同,即@Cacheable(key = "XXX")相同,此时service层的覆盖mapper层的缓存。 - 所以如果出现了缓存加在service和mapper层都可以的情况,我们考虑优先加在mapper层(考虑之后其他的mapper层可能会通过@Query调用)。但是service层也要加命名空间CacheConfig(cacheNames = "xx"),考虑有可能会在service层加其他缓存。但是删除缓存的操作均在service层。
- 下面我以用户user与岗位job(多对多)两个实体类来详细说明缓存的添加与维护。
情况一:单一实体缓存,key和value都仅与该实体相关(1:1)
- 首先是针对一个实体的单条信息进行缓存,key和value都和一个实体有关。如缓存job表的每一条记录,以id和键名,Job实体为value存入缓存:
在JobMapper加上命名空间 @CacheConfig(cacheNames = "job") - 首先在JobMapper加上命名空间:
@CacheConfig(cacheNames = "job")
public interface JobMapper extends BasicMapper<Job> {- 虽然BaseMapper
已经提供了根据id查询—— T selectById(Serializable id);
重写selectById,并加上@Cacheable - 但是咱们需要加上缓存,所以需要重新在mapper层写该方法(无需写sql),并加上@Cacheable,此时键名key的命名规则为统一的 "'id:' + #p0" ,id指Job的id,#p0指方法的第一个参数:
@Cacheable(key = "'id:' + #p0")
Job selectById(Long id);- 此时springboot会将第一查询的结果放入缓存,之后无论是从service调mapper的该方法,还是从mapper的@Query中调用该方法都可以走缓存。
- 缓存情况如下图:
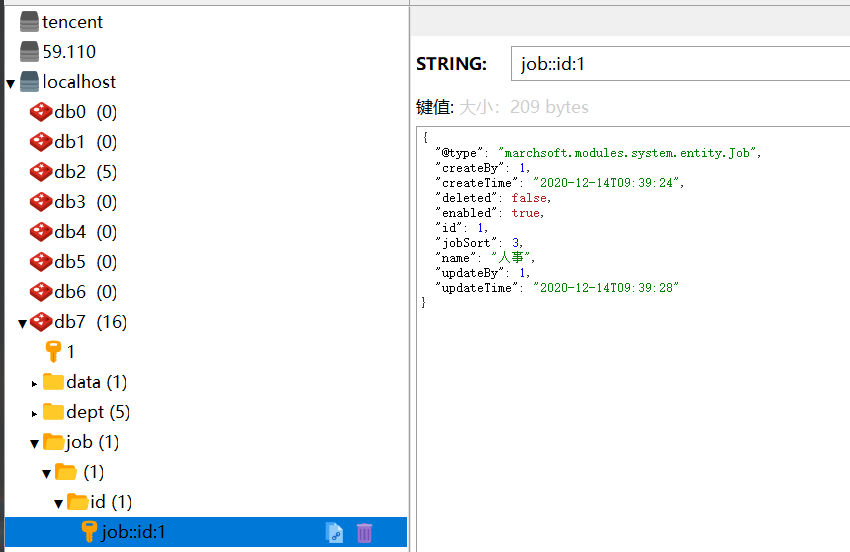
将键名除id外以静态变量存入CacheKey - 可以看到我们成功把id为1的job存入了redis缓存,该缓存的value即为Job实体类,键名为 job::id:1 ,其中为了后期维护缓存方便,我们将字符串 "job::id:" 作为静态变量存入 CacheKey.class中,在做维护时只需拼接一个id即可:
public interface CacheKey {
/**
* 用户
*/
String USER_ID = "user::id:";
/**
* 数据
*/
String DATA_USER = "data::user:";
/**
* 菜单
*/
String MENU_ID = "menu::id:";
String MENU_USER = "menu::user:";
String MENU_ROLE = "menu::role:";
/**
* 角色授权
*/
String ROLE_AUTH = "role::auth:";
String ROLE_USER = "role::user:";
/**
* 角色信息
*/
String ROLE_ID = "role::id:";
/**
* 部门信息
*/
String DEPT_ID = "dept::id:";
String DEPT_ROLE = "dept::role:";
/**
* 岗位信息
*/
String JOB_ID = "job::id:"; //示例
String JOB_USER = "job::user:";
}
在对应的service层手动维护缓存
- 这里为了统一建议手动维护缓存,即在JobServiceImpl下手写一个方法来清理缓存,在相应的更新、删除Job的地方调用该方法即可:
/**
* 清理缓存
* @param id job_id
*/
private void delCaches(Long id){
redisUtils.del(CacheKey.JOB_ID + id);
}- 你也可以在相应的更新、删除的方法上加上springboot删除缓存的注解(不推荐,后期缓存情况复杂)
@CacheEvict(key = "'id:' + #p0.id")
public void update(Job resources) {}
对于单一实体的缓存,仅缓存 selectById方法,对于该实体的分页查询等其他条件查询一般不做缓存,除非有特殊要求
情况二:缓存内容关联两个及以上的实体(1:n,n:m)
- 这类缓存是比较令人头疼的地方,我们之前有规定,@Query中所调用的方法必须要有缓存,这里user与job是多对多的关系,有一张中间sys_users_jobs,当我们在查询一个用户时要连带将其所有的岗位也查找出来:
//UserMapper中查询一个用户
@Select("SELECT id,dept_id,username,nick_name,gender,phone,email,avatar_path,password," +
"is_admin,enabled,create_by,update_by,pwd_reset_time,create_time,update_time" +
" FROM sys_user u WHERE u.id = #{id} AND is_deleted=0")
@Results({
@Result(column = "id", property = "id"),
@Result(column = "dept_id", property = "deptId"),
})
@Queries({
@Query(column = "id", property = "roles",
select = "marchsoft.modules.system.mapper.RoleMapper.findWithMenuByUserId"),
@Query(column = "id", property = "jobs",
select = "marchsoft.modules.system.mapper.JobMapper.findByUserId"), //这里
@Query(column = "dept_id", property = "dept",
select = "marchsoft.modules.system.mapper.DeptMapper.selectById")
})
@Cacheable(key = "'id:' + #p0")
UserBO findUserDetailById(Long id);- 既然通过@Query调用了JobMapper.findByUserId方法,我们就需要对其加缓存(其他的同理)
//JobMapper中根据用户id查询岗位
@Select("SELECT j.id, j.name, j.enabled, j.job_sort, j.create_by, j.update_by, j.create_time, j.update_time " +
"FROM sys_job j, sys_users_jobs uj WHERE j.id = uj.job_id AND uj.user_id = ${id} AND j.is_deleted=0")
@Cacheable(key = "'user:' + #p0")
Set<Job> findByUserId(Long id);-
此时缓存的命名规则为 key = "'user:' + #p0" ,这里的user指user_id的意思,后面的参数#p0就是user_id,我们可以发现此时的redis里缓存全称为: job::user:2
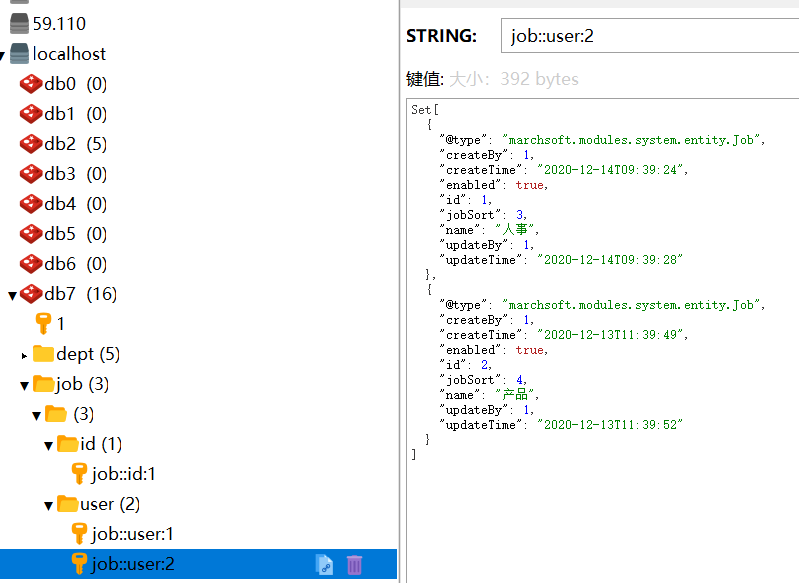
-
意思即为user_id为2的用户所拥有的job,从value中可以看出该用户有两个job。我们也需要将 "job::user:" 存入 CacheKey中,命名为 JOB_USER (可以回看上面的)。
从每个与该缓存相关的实体的service层对其进行维护 -
以 job::user:2 缓存维护为例
Job发生删改时,可能需要对改缓存进行维护 -
当我们修改了一个id为1的job,可能id为2的user有这个job,也可能没有,有的话必须删除该缓存,即我们需要通过sys_users_jobs关系表找到含有job_id=2的user_id的集合,是一个List
:
//UserMapper下
//根据job_id查询用户Id (清理job缓存时调用)
@Select("SELECT user_id FROM sys_users_jobs WHERE job_id = #{id} group by user_id")
List<Long> findByJobId(Long id);- 注意,这里是因为job的变动导致需要清理该缓存,所以该部分清理缓存的代码写在 JobServiceImpl下的delcache方法中:
//JobServiceImpl
private void delCaches(Long id){
List<Long> userIds = userMapper.findByJobId(id);
redisUtils.delByKeys(CacheKey.JOB_USER, new HashSet<>(userIds)); //第二种情况所删的缓存
redisUtils.del(CacheKey.JOB_ID + id); //第一种情况所删的缓存
}
当中间表sys_users_jobs发生变动时,一定要清理缓存!
- 当我们修改了user的job时,如上图user_id = 2的用户有两个job,我们将其调整为一个job,此时也需要删除 job::user:2 这条缓存,由于是因为更新了user才导致删除这条缓存,所以该部分代码写在 UserServiceImpl的更新、删除中:
//UserServiceImpl下的更新user方法
public void updateUserWithDetail(UserInsertOrUpdateDTO userInsertOrUpdateDTO) {
//...
//如果岗位发生变化
if (! CollectionUtils.isEqualCollection(jobIds, userInsertOrUpdateDTO.getJobs())) {
//...
//清除缓存
redisUtils.del(CacheKey.JOB_USER + userInsertOrUpdateDTO.getId());
}
//...
}- 这样,我们才算是对 job::user:2这条缓存做了完全的维护。
对于情况一的缓存只涉及一个实体(表),缓存维护比较好实现,针对第二种情况需要我们考虑全面,在哪些地方需要去维护,这个需要考虑清除,不要随意加缓存
谁加了哪个缓存,谁就有义务去维护它!