Antlr (ANother Tool for Language Recognition) 是一款强大的语法分析器生成工具,可用于读取、处理、执行和翻译结构化的文本或者二进制文件。它被广泛应用于学术领域和工业生产实践,是众多语言、工具和框架的基石。我们可以使用Antlr来开发DSL(Domain Specific Language,领域特定语言),或者一些实用工具,比如配置文件读取器、遗留代码转换器和Json解析器等等。
概念
大白话说,这东西就是用来校验和分析某个特定语言或语法的工具。那么这个特定的语言就是咱们实现编写好的g4文件,包含了要识别语言的词法规则和语法规则。然后我们就可以使用Antlr工具来将该语法文件转换成可以识别该语法文件所描述语言的程序。
举个例子来说的话,就是给定一个识别JSON的语法,antlr工具将会根据该语法生成一个程序,此程序可以通过antlr运行库来识别输入的JSON,即输入的字符串是否符合JSON格式。
但是更加强大的是antlr给予开发者去监听antlr解析的过程,那我们就可以在代码中去提取被校验字符串的特定部分,从而实现一些功能。
使用
-
打开IDEA,在File—Settings—Plugins中,安装ANTLR v4 grammar plugin插件
-
添加pom依赖
<dependencies> <dependency> <groupId>org.antlr</groupId> <artifactId>antlr4-runtime</artifactId> <version>4.8-1</version> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.antlr</groupId> <artifactId>antlr4-maven-plugin</artifactId> <version>4.8-1</version> <executions> <execution> <id>antlr</id> <goals> <goal>antlr4</goal> </goals> <phase>none</phase> </execution> </executions> <configuration> <outputDirectory>src/test/java</outputDirectory> <listener>true</listener> <treatWarningsAsErrors>true</treatWarningsAsErrors> </configuration> </plugin> </plugins> </build>
demo
我们可以新建一个g4文件,写一个json字符串的校验g4文件,具体的语法和词法规则大家有兴趣可以网上搜一下:
grammar JSON;
// 一个JSON文件可以是一个对象,或者是由若干个值组成的数组
json : object
| array
;
// 一个对象是一组无序的键值对集合。一个对象以一个左花括号{开始,且以右花括号}结束。
// 每个键后跟一个冒号:,键值对之间由逗号,分隔
object : '{' pair (',' pair)* '}'
| '{' '}'
;
pair : STRING ':' value;
// 数组是一组值的有序集合。一个数组由一个左方括号[开始,并以一个右方括号]结束。
// 其中的值由逗号,分隔
array : '[' value (',' value)* ']'
| '[' ']'
;
// 一个值可以是一个双引号包围的字符串、一个数字、true\false、null、一个对象、或者一个数组。
value : STRING
| NUMBER
| 'true'
| 'false'
| 'null'
| object
| array
;
// 一个字符串就是一个由零个或多个Unicode字符组成的序列,它由双引号包围,其中的字符使用反斜杠转义。
// 单个字符由长度为1的字符串表示
STRING : '"' (ESC | ~["\\])* '"';
fragment ESC : '\\' (["\\/bfnrt] | UNICODE);
fragment UNICODE : 'u' HEX HEX HEX HEX;
fragment HEX : [0-9a-fA-F];
// 一个数字和C/Java中的数字非常相似,除了一点之外:不允许使用八进制和十六进制
NUMBER
: '-'? INT '.' [0-9]+ EXP? // 1.35, 1.35E-9, 0.3, -4.5
| '-'? INT EXP // 1e10 -3e4
| '-'? INT // -3, 45
;
fragment INT : '0' | [1-9] [0-9]* ; // 除零外的数字不允许以0开始
fragment EXP : [Ee] [+\-]? INT ; // \- 是对-的转义,因为[...]中的-用于表示“范围”
WS : [ \t\n\r]+ -> skip ;我们右键点击 Configure Antlr可以选择输出位置,之后再右键点击 Generate ANTLR Recognizer 生成xxxLexer,xxxParser,xxxBaseListener,xxxBaseVisitor等文件,其中我们可以继承xxxBaseListener,通过重写其中的visit方法,便可以监听某些节点的字符串信息,并做处理。
我们还可以右键某个词法定义(一般选最顶层的节点),右键 Test Rule xxx,即可把我们要检测的字符串输入进左方,右方便会生成一个解析树,树上的节点既是我们实现定义好的词法:
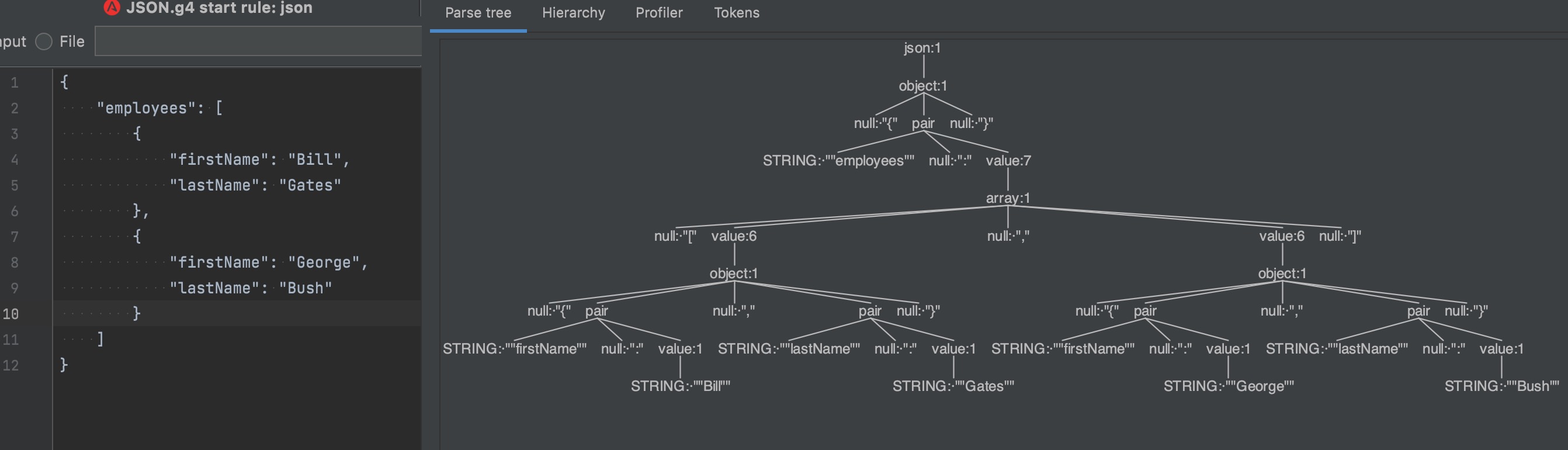
如果输入的字符串不符合g4里的规则,解析树就会在相应的位置爆红色错误。
xxxBaseListener,xxxBaseVisitor,即两种解析模式,这两个才是精华所在,我会在 基于Antlr对PostgreSql血缘解析 这篇文章中详细说明其使用方法