上一篇文章讲了antlr的一个简单上手使用,这篇主要说下他的一个重要作用,就是解析sql,并提取其中表、字段信息,同时记录血缘关系,最后将其存入atlas中。
首先我们需要有 postgreSql的g4文件,当然这个肯定不是让你写的,否则累死了,我能在网上找到的postgreSql.g4是在两个地方,首先是 antlr 的github官网 有这个,但很可惜他解析出来的是csharp文件,我们java用不了,所以使用的是另一个民间大神的g4文件 antlr_psql
有了 g4 文件,我们便可以生成最重要的 Parser 文件:
其次我要说下antlr里一些比较重要的概念
RuleNode
我们g4文件里定义的一个个规则在 antlr 看来都是一个个的节点,比如 select、from、GROUP BY等,而正是这么多若干的RuleNode最后形成了我们一颗大的解析树:
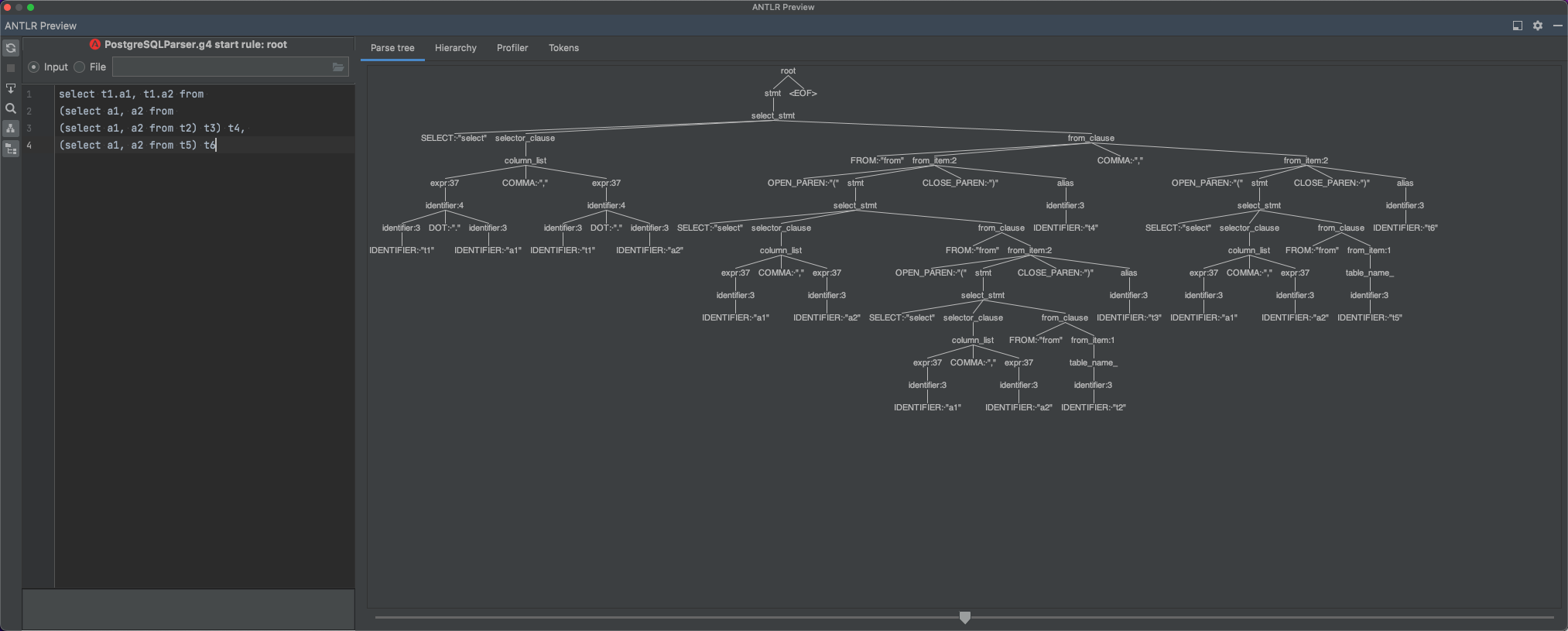
类似这个解析树里的一个个节点:select_stmt、colum_list等,这些也都是一开始定义在g4文件里的
然后是访问解析树的两种模式:监听者模式 和 访问者visitor模式,我这里主要说visitor模式
Visitor模式
PostgreSQLParserVisitor.java是个访问器接口,定义了一些访问RuleNode的接口方法,可以通过实现它来完成自定义的功能。而PostgreSQLParserBaseVisitor.java是该接口的默认实现,它为每个接口方法提供了空实现。
我们可以自己写一个类继承 PostgreSQLParserBaseVisitor ,并重写自己想要处理节点的方法,即可做自己的处理:
例如上图,我们能从解析树中看到 select_stmt这个节点,我们可以通过访问这个节点拿到它下面的列,再而即可拿到字段名字,而重写方法名只用在前面加上visit即可:
public class PostgreSqlFieldLineageParser extends PostgreSQLParserBaseVisitor {
@Override
public Object visitSelect_stmt(PostgreSQLParser.Select_stmtContext ctx) {
ctx.selector_clause().column_list().expr().forEach( exprContext -> {
exprContext.identifier().forEach(identifierContext -> {
System.out.println("visitSelect_stmt : " + identifierContext.getRuleContext().getText());
});
});
return super.visitSelect_stmt(ctx);
}
}
这样我们就可以在 antlr 访问解析树时拿到想要的字段,其中PostgreSQLParser.Select_stmtContext ctx 就是select_stmt节点的上下文,我们可以拿到它父子节点的值。
但是主要我们最后要 return 父级该方法,这是和监听器机制的不同:
我们调用visit方法即可访问节点信息:
//调用该方法
public void parseSqlFieldLineage(String sql) {
PostgreSqlFieldLineageParser visitor = new PostgreSqlFieldLineageParser();
visitor.visit(getParseTree(sql));
}
private ParseTree getParseTree(String sql) {
CharStream input = CharStreams.fromString(sql);
PostgreSQLLexer lexer = new PostgreSQLLexer(input);
CommonTokenStream tokenStream = new CommonTokenStream(lexer);
PostgreSQLParser parser = new PostgreSQLParser(tokenStream);
return parser.root();
}如果我们要拿到 from 后的表名,同理:
@Override
public Object visitFrom_clause(PostgreSQLParser.From_clauseContext ctx) {
PostgreSqlFieldModel postgreSqlFieldModel = map.get(lastHashcode);
ctx.from_item().forEach(from_itemContext -> {
//别名
if (from_itemContext.alias() != null) {
System.out.println("from : " + from_itemContext.alias().identifier().getRuleContext().getText());
}
//表名
if (from_itemContext.table_name_() != null) {
System.out.println("from : " + from_itemContext.table_name_().getRuleContext().getText());
}
});
return super.visitFrom_clause(ctx);
}由此我们还可以得出结论,当有子查询的时候visitSelect_stmt方法会访问多次,因为select_stmt节点可能会有多个,每次只能得到当前节点子节点的一些值,但我们需要知道
visitor模式访问解析树是深度优先
(记录父子节点关系的具体代码后续更新,列血缘比较麻烦,有一些别名、计算类的情况没有完善到)
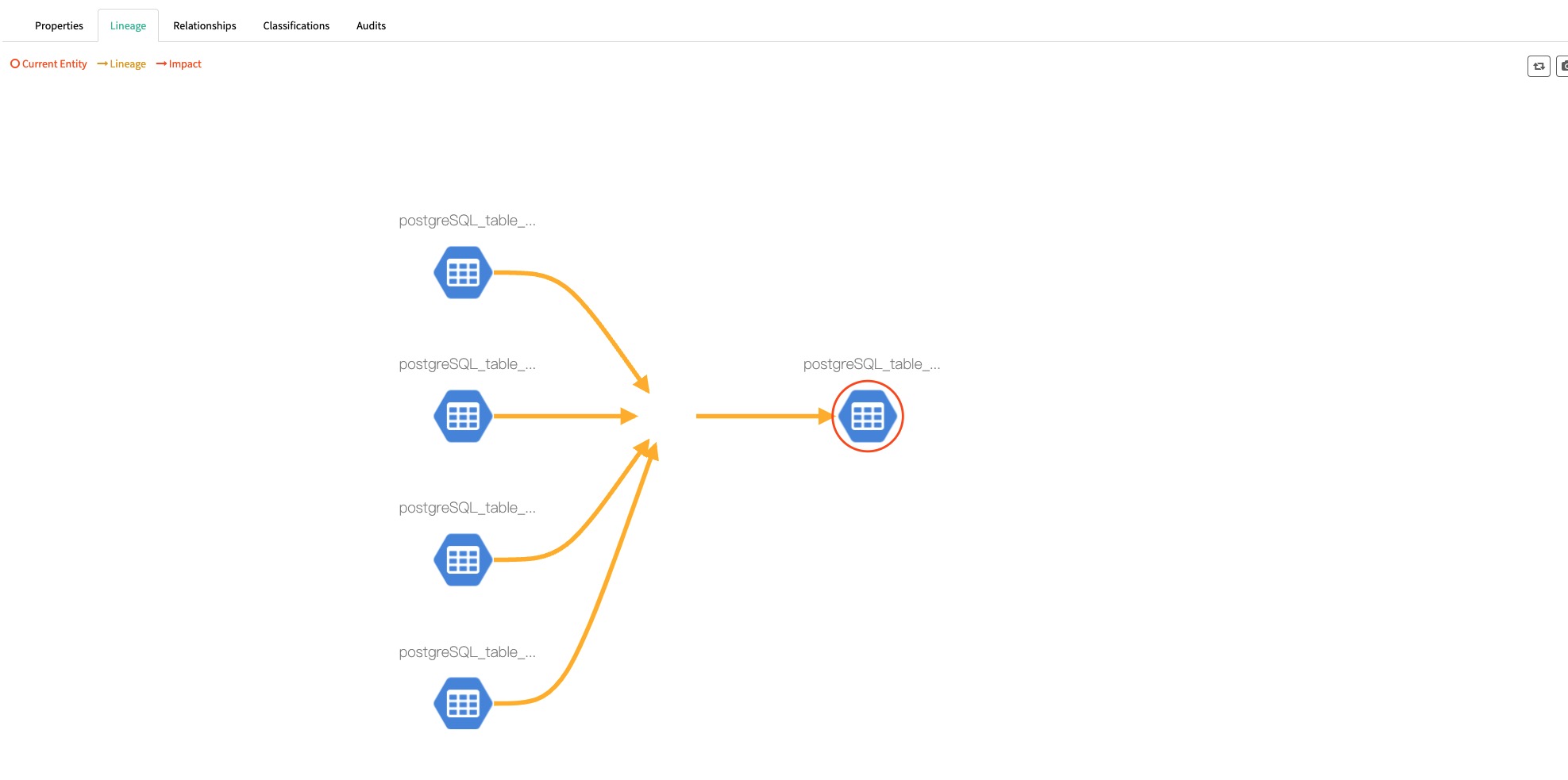
存入atlas
当我们有了表与表、列于列之间的关系的时候,便可以通过rest API存入atlas,我这里通过 AtlasClientV2
1 条评论
大佬 有demo吗