up目前的主要工作是做SQL解析,提取元数据信息和血缘信息。对于市场上相对成熟的SQL解析工具,如 calcite、druid(内含解析),这些活跃度高、解析速度也快,但是有一个通病是方言支持度不高,虽然可以扩展,但是也有些难度。(calcite使用jj,而druid是手写的词法解析和语法解析)。
从易扩展的角度目前我先选择了使用antlr解析SQL,因为g4方便扩展,github社区也有很多现成的g4文件可以使用。
而我目前主要解析 hive ,antlr官方语法库 grammer-v4 里也有相应的g4文件,我便直接使用进行解析。
但是在使用中就发现了 expression 规则定义的问题:and/or 没有优先级。
举个例子
SELECT c1, c2 FROM t1 WHERE c1 > 1 AND c2 < 3;我们看看修改前的解析树长什么样:
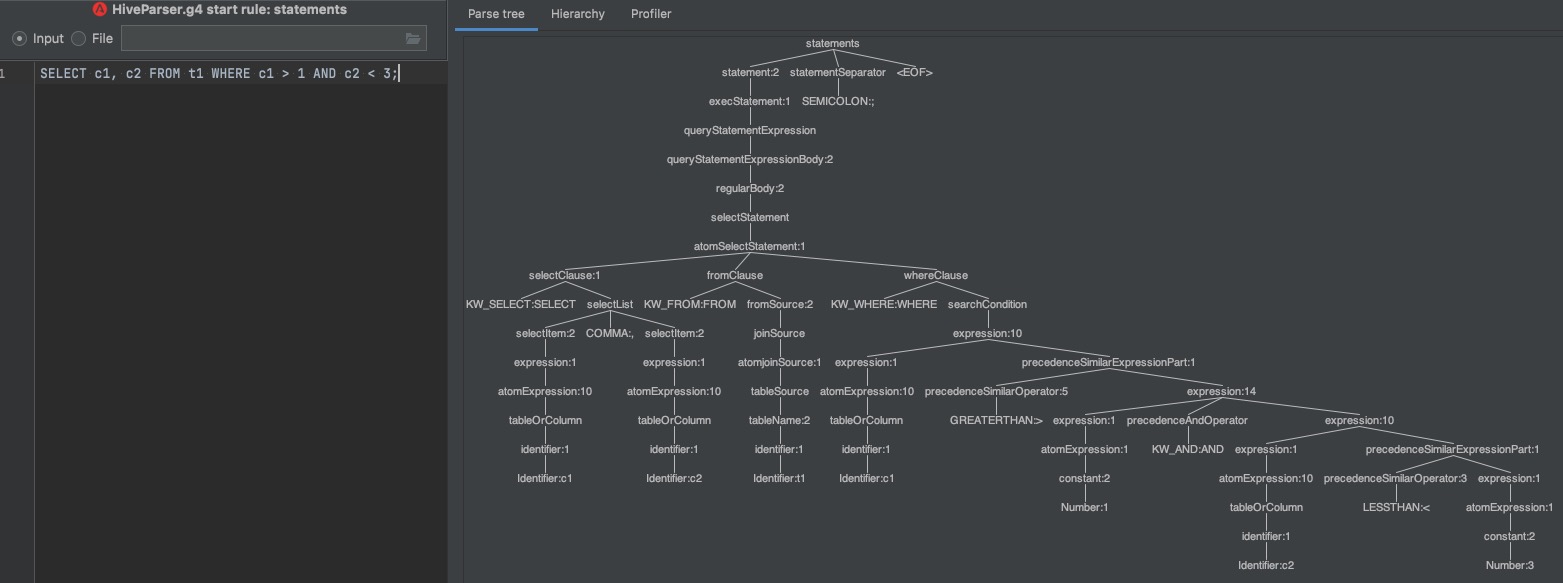
我们可以看到右下部分中,WHERE条件通过操作符构成的树是不平衡的,也就是并没有区分 > AND < 这三个操作符的优先级。如果你的解析力度并不是很高,可以忽略此问题,但是很明显如果你要做还原的话这里就会出些问题,或者说会很繁琐。
那么,我们来看看修改后的解析树:
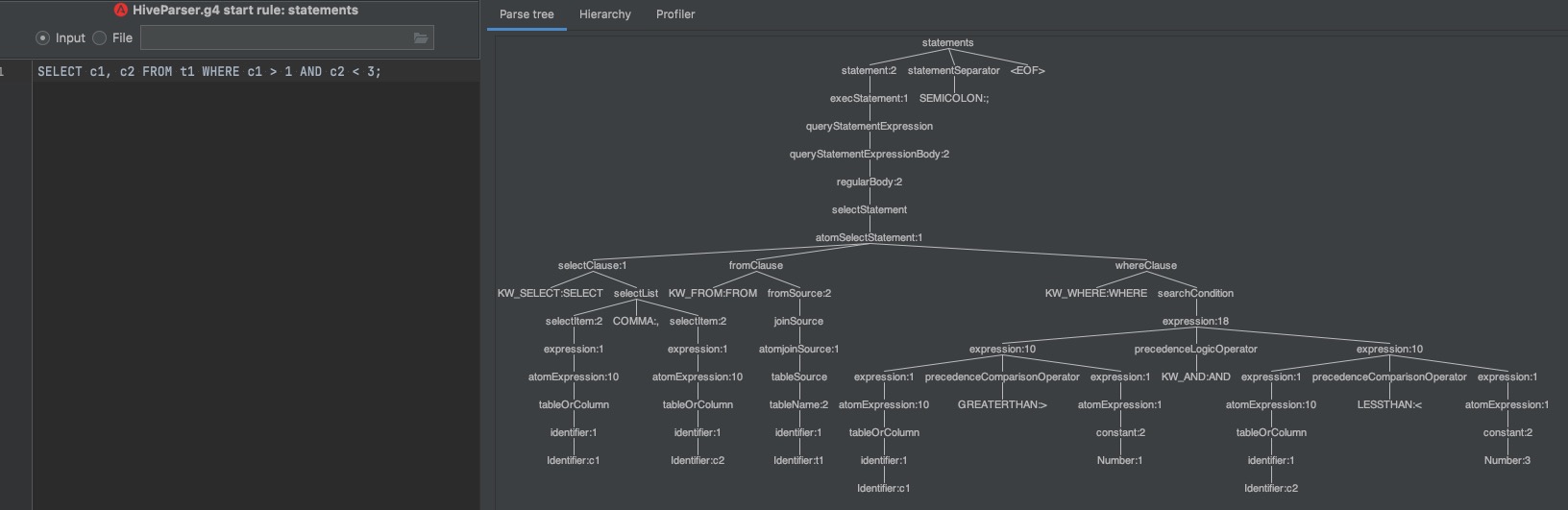
很显然,更改之后的解析树平衡了,而且可以根据 AND/OR 间断还原左右 expression,这对我自己接下来的开发工作带来了很大的帮助。
但是我毕竟修改也都修改过了,何不比直接提交给antlr官方,之后就不会有人遇到相应的问题了:
我不仅修改了 AND/OR 优先级的问题,同时对原有 expression 中相应语法规则名称进行了重定义,因为原先的定义有些冗余、乱,对解析带来了不小的麻烦。
提交给antlr之后,也是很快,审核人就给我修改的部分提出了一些 suggestion,我就根据他的 suggestion 又修改了部分代码,之后就是进入了漫长的自动化测试,一共二十多个,终于在晚饭结束之后,我到了 PR 被合并的通知。
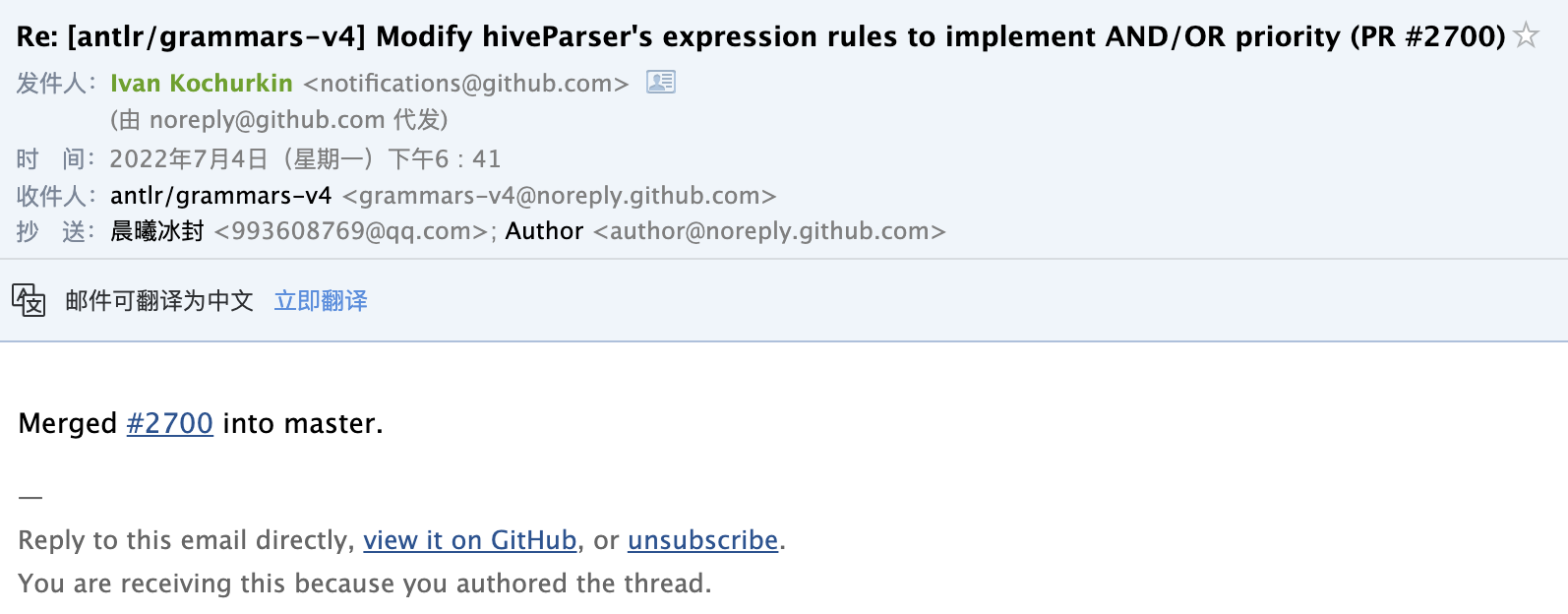
我也是十分高兴,非常感谢 #Ivan Kochurkin 对我的建议和认可,我也跟高兴能为antlr仓库带来一些贡献!

我们公司的 #绝云大 对此与给予我了肯定和鼓励:
我觉得开源也是我们与世界的一种相处模式:充满好奇,追求自由,坚持 DRY,平等包容,打磨技艺等等,这是这群人共同信奉的东西。
所以大家能跨越大洋国境的界限一同协作解决一个有趣的问题,让世界变得更好一点点。以开放待世界,世界也会回以拥抱,开源社区常说“保持正确的态度,有趣的事情自然会找到你”。
这是一个挺值得工程师去学习成长的地方,祝 #皆非 在社区走得更远。

这将是我在开源的道路上留下的又一个重要的脚印,继续加油,砥砺前行!