因为我是元数据组的,,所以之后基本上都是在和元数据打交道,我所需要学习的第一个重要框架就是Atlas,但是目前关于它还暂时只有英文文档,所以只能硬着翻译学习
概览
Atlas 是一组可扩展和可延伸的核心基础治理服务, Apache Atlas 为组织提供开放的元数据管理和治理功能,以构建其数据资产的目录,对这些资产进行分类和治理。
元数据
我们先来聊一聊什么是元数据,元数据比较多的一个解释为“数据的数据”,是更为抽象的一层。
例如我们使用最的的关系数据库mysql,我们如果要存储学生信息,首先要建一个库,其次再一个学生表student,之后再一条一条的存储学生信息。
那么问题来了,描述“库”、和“表”的信息在哪呢?一个库需要有库名、库的存储引擎、字符集等信息,表有表名、行格式、索引等信息,这些在我们业务数据之上的数据,就称作为元数据,是更为抽象的一层数据。
Atlas架构
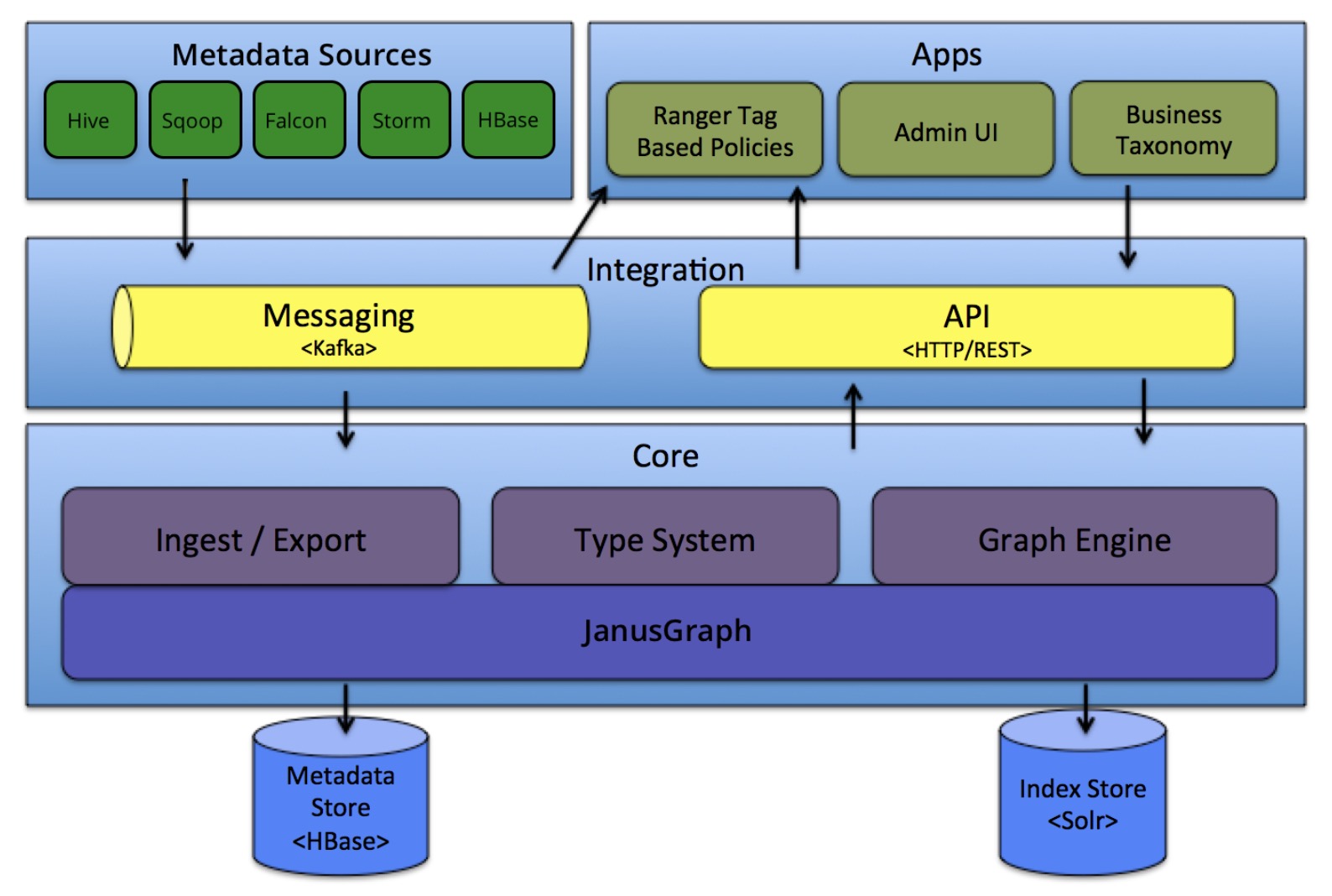
这个是Atlas的架构图,我们把目光聚焦在 Core 这一核心层,可以看出Atlas的核心组件有:Ingest/Export、Type System、Graph Engine
Type System
Type System 类型系统
首先我们称类型 type 为一个元数据对象(如hive表)的模型(可以类比 java 中的 class ),若干 type 便组成了 types ,每一个 type 所对应的实例为实体 entity ,若干entity组成entities。
那么Type System 是一个允许用户定义和管理 entities 和 types 的组件
类型
实体
属性
Graph Engine
图引擎用来持久化所管理的元数据对象,可以将 types 和 entities 相互转化。还对元数据对象创建索引,便于对元数据对象搜索
其调用 JenusGraph 是一个图数据库,来实际的存储元数据对象,由 Graph Engine 所调用,其会构建不同元数据对象之间的关系,形成图谱存入hive
Ingest/Export
元数据的导入和导出
Integration
一体化:提供两种方式来管理 Atlas 中的元数据。
一个是通过对外暴露的 rest 接口,可以直接http调用;另一个是通过消息传递机制,在元数据源采集时,每个源都有对应的 hook ,例如元数据源为 hive 时就有 hive hook ,会将即时变化的 数据 缓存至 kafka 中,而 atlas 则会订阅其相关主题来消费新变化的数据
web
Atlas 自带的一个web管理页面,可以查询元数据类型和对象,是一个类似于sql的查询
血缘分析
血缘分析是一种技术手段,用于对数据处理过程的全面追踪,从而找到某个数据对象为起点的所有相关元数据对象以及这些元数据对象之间的关系。
元数据对象之间的关系特指表示这些元数据对象的数据流输入输出关系。
通常我们会对原始数据进行多个步骤的各种加工,最后产生出新的数据,在这个过程中会产生很多表,这些数据表之间的链路关系就可称为大数据血缘
大数据血缘测试,就是测试数据流转过程中的每个环节的数据质量
在现实世界中,我们每个个体都是祖先通过生育关系一代代孕育而来,这样就形成了我们人类的各种血缘关系。
在数据信息时代,每时每刻都会产生庞大的数据,即我们通常说的大数据,对这些数据进行各种加工组合、转换,又会产生新的数据,这些数据之间就存在着天然的联系,我们把这些联系称为数据血缘关系。
直白点说,数据血缘就是指数据产生的链路关系,就是这个数据是怎么来的,经过了哪些过程和阶段。
例子
比如在淘宝网中,客户在淘宝网页中购买物品后,数据就被存到后台数据库表A中。我们希望查看某个月卖的最火的是哪些物品时,就需要对数据库中的原始数据进行加工汇总,形成一张中间表B来存储阶段处理的数据,若逻辑较复杂时,还要继续加工继续形成中间表。。。直到最后处理成我们前台展现使用的最终表,假设为C表。
那么A表是C表数据最初的来源,是C表数据的祖先。从A表数据到B表数据再到C表数据,这条链路就是C表的数据血缘。

加速数据处理
很多银行在生成各类全局指标的过程中,需要大量的计算工作,往往只能满足T+1.5(1T代表1天)的要求,昨天的数据,要等到明天中午才能看。
尽管这样的效率已经不能够让业务部门满意,技术部门因此承担着巨大的压力,最让技术部门烦恼的还不只是如此,而是原始采集的数据可能因为各种各样的问题,在数据处理中做很多调整。我们这些做技术的,都能理解技术部门烦恼的原因。试
想一下,原本一个5个小时左右的处理任务,在运行4.5小时以后,即将完成,突然有人告诉你,最初给定的数据有问题,现在必须得改,而且还希望你能在1个小时内把数据算出来。借助血缘分析,这个方案有很大的提升空间。
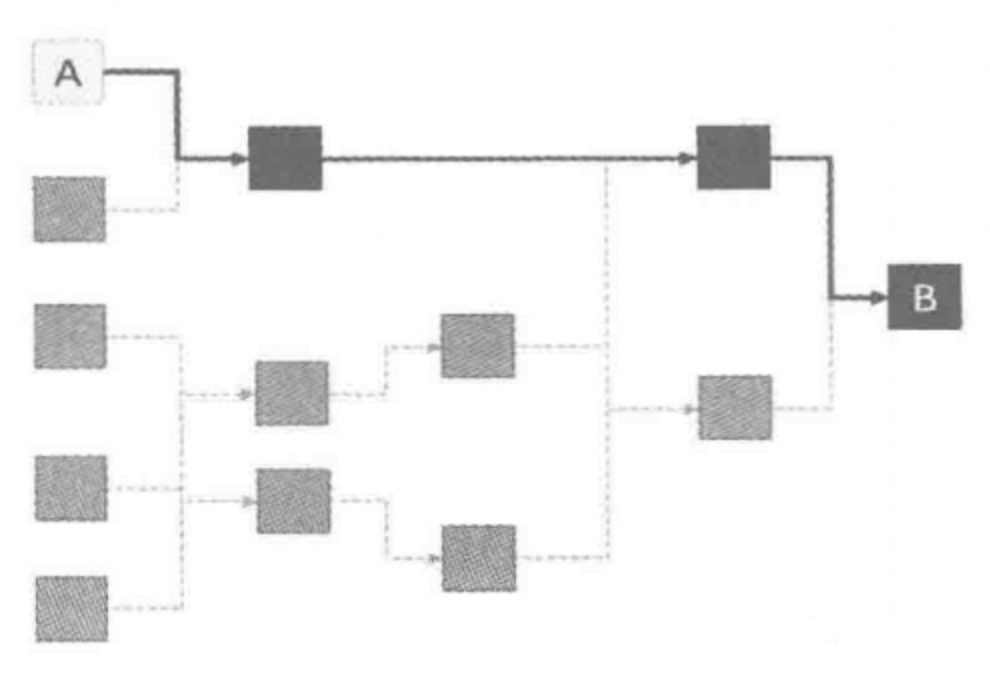
如上图所示,在生成指标B的过程,输入表A进行了变更,如果通过血缘分析,了解到了A所影响的路径范围,那么完全不必要重新做一次所有计算任务,而只是把A到B之间影响到的节点重新加工即可。这样计算量可以大大缩减,而且提高任务的弹性时间,或许1小时内就能完成调整后的计算。