JMH,即Java Microbenchmark Harness,这是专门用于进行代码的微基准测试的一套工具API。官方code sample。
概览
何谓 Micro Benchmark 呢? 简单地说就是在 method 层面上的 benchmark,精度可以精确到微秒级。
Java的基准测试需要注意的几个点:
- 测试前需要预热。
- 防止无用代码进入测试方法中。
- 并发测试。
- 测试结果呈现。
比较典型的使用场景:
- 当你已经找出了热点函数,而需要对热点函数进行进一步的优化时,就可以使用 JMH 对优化的效果进行定量的分析。
- 想定量地知道某个函数需要执行多长时间,以及执行时间和输入 n 的相关性
- 对比接口不同实现在给定条件下的吞吐量
- 查看多少百分比的请求在多长时间内完成
例子
依赖
创建 maven 项目后添加依赖:
<!-- JMH-->
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-core</artifactId>
<version>${jmh.version}</version>
</dependency>
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-generator-annprocess</artifactId>
<version>${jmh.version}</version>
<scope>provided</scope>
</dependency>编写性能测试
接下来我写一个比较字符串连接操作的时候,直接使用字符串相加和使用StringBuilder的append方式的性能比较测试
@BenchmarkMode(Mode.AverageTime)
@Warmup(iterations = 3, time = 1)
@Measurement(iterations = 5, time = 5)
@Threads(4)
@Fork(1)
@State(value = Scope.Benchmark)
@OutputTimeUnit(TimeUnit.NANOSECONDS)
public class StringConnectTest {
@Param(value = {"10", "50", "100"})
private int length;
@Benchmark
public void testStringAdd(Blackhole blackhole) {
String a = "";
for (int i = 0; i < length; i++) {
a += i;
}
blackhole.consume(a);
}
@Benchmark
public void testStringBuilderAdd(Blackhole blackhole) {
StringBuilder sb = new StringBuilder();
for (int i = 0; i < length; i++) {
sb.append(i);
}
blackhole.consume(sb.toString());
}
public static void main(String[] args) throws RunnerException {
Options options = new OptionsBuilder()
.include(StringBuilderBenchmark.class.getSimpleName())
.output("/Users/jiefei/data/benchmark/Benchmark.log")
.build();
new Runner(options).run();
}
}执行方式
运行JMH基准测试有多种方式,一个是生成jar文件执行, 一个是直接写main函数或写单元测试执行
一般对于大型的测试,需要测试时间比较久,线程比较多的话,就需要去写好了丢到linux程序里执行:
JMH 官方提供了生成 jar 包的方式来执行,我们需要在 maven 里增加一个 plugin,具体配置如下:
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.1</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<finalName>jmh-demo</finalName>
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>org.openjdk.jmh.Main</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>mvn clean package
java -jar target/benchmarks.jar另外如果对于一些小的测试,比如我写的上面这个小例子,在IDE里面就可以完成了,丢到linux上去太麻烦。 这时候可以在里面添加一个main函数如下:
public static void main(String[] args) throws RunnerException {
Options options = new OptionsBuilder()
.include(StringBuilderBenchmark.class.getSimpleName())
.output("/Users/jiefei/data/benchmark/Benchmark.log")
.build();
new Runner(options).run();
}这种输出方式是直接输出信息到log,文件,如果想输出结果为json格式则:
public static void main(String[] args) throws RunnerException {
Options opt = new OptionsBuilder()
.include(StringConnectTest.class.getSimpleName())
.result("/Users/jiefei/data/benchmark.json")
.resultFormat(ResultFormatType.JSON)
.build();
new Runner(opt).run();
}这里其实也比较简单,new个Options,然后传入要运行哪个测试,选择基准测试报告输出文件地址,然后通过Runner的run方法就可以跑起来了。
结果
打开刚刚的log文件,我们可以发现有三大部分,第一部分是字符串用加号连接执行的结果,第二部分是StringBuilder执行的结果,第三部分就是两个的简单结果比较。这里注意我们forks传的2,所以每个测试有两个fork结果。
前两部分是一样的,简单说下。首先会写出每部分的一些参数设置,然后是预热迭代执行(Warmup Iteration), 然后是正常的迭代执行(Iteration),最后是结果(Result)。
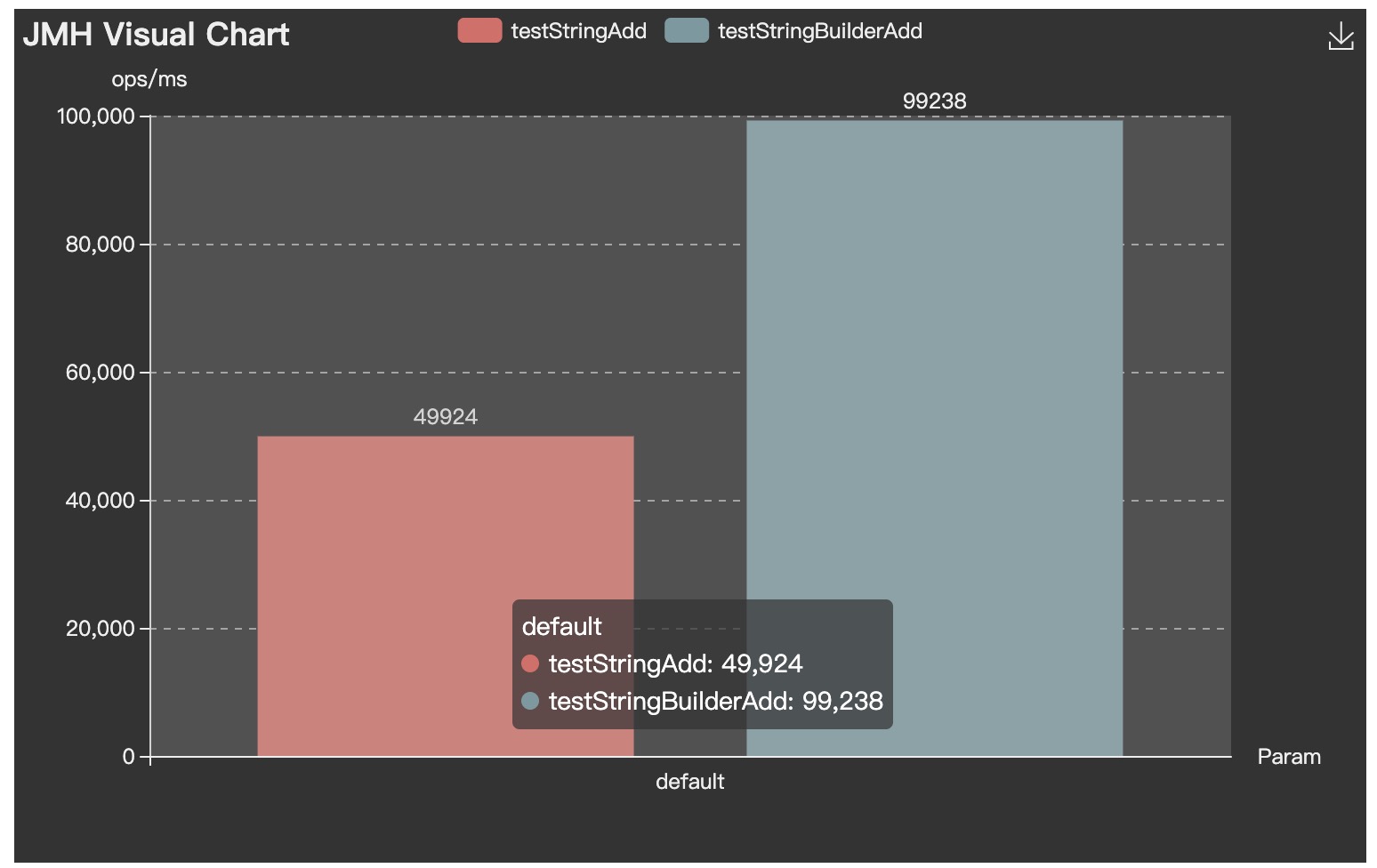
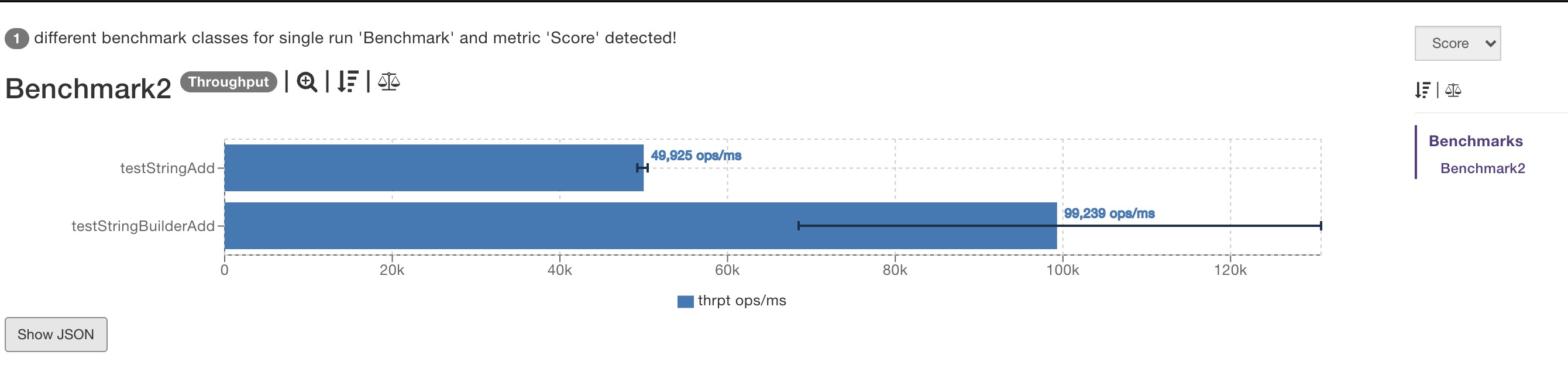
这些看看就好,我们最关注的就是第三部分, 其实也就是最终的结论。error那列其实没有内容,score的结果是xxx ± xxx,单位是每毫秒多少个操作。
可以看到,StringBuilder的速度还确实是要比String进行文字叠加的效率好太多。
注解介绍
@BenchmarkMode
基准测试类型。这里选择的是Throughput也就是吞吐量。根据源码点进去,每种类型后面都有对应的解释,比较好理解,吞吐量会得到单位时间内可以进行的操作数。
- Throughput: 整体吞吐量,例如”1秒内可以执行多少次调用”,单位为 ops/time
- AverageTime: 调用的平均时间,例如”每次调用平均耗时xxx毫秒”,单位为 time/op
- SampleTime: 随机取样,最后输出取样结果的分布,例如”99%的调用在xxx毫秒以内,99.99%的调用在xxx毫秒以内”
- SingleShotTime: 以上模式都是默认一次 iteration 是 1s,唯有 SingleShotTime 是只运行一次。往往同时把 warmup 次数设为0,用于测试冷启动时的性能。
- All(“all”, “All benchmark modes”);上面的所有模式都执行一次
@Warmup
一般我们前几次进行程序测试的时候都会比较慢, 所以要让程序进行几轮预热,保证测试的准确性。
- iterations:预热的次数
- time:每次预热的时间
- timeUnit:时间的单位,默认秒
- batchSize:批处理大小,每次操作调用几次方法
@Measurement
度量,其实就是一些基本的测试参数。
- iterations 进行测试的轮次
- time 每轮进行的时长
- timeUnit 时长单位
@Threads
每个进程中的测试线程,这个非常好理解,根据具体情况选择,一般为cpu乘以2。
@Fork
进行 fork 的次数。如果 fork 数是2的话,则 JMH 会 fork 出两个进程来进行测试。
@OutputTimeUnit
这个比较简单了,基准测试结果的时间类型。一般选择秒、毫秒、微秒。
@Param
属性级注解,@Param 可以用来指定某项参数的多种情况。特别适合用来测试一个函数在不同的参数输入的情况下的性能。
@Setup
方法级注解,这个注解的作用就是我们需要在测试之前进行一些准备工作,比如对一些数据的初始化之类的。
@TearDown
方法级注解,这个注解的作用就是我们需要在测试之后进行一些结束工作,比如关闭线程池,数据库连接等的,主要用于资源的回收等。
@State
State 用于声明某个类是一个”状态”,然后接受一个 Scope 参数用来表示该状态的共享范围。 因为很多 benchmark 会需要一些表示状态的类,JMH 允许你把这些类以依赖注入的方式注入到 benchmark 函数里。Scope 主要分为三种。
- Thread: 该状态为每个线程独享。
- Group: 该状态为同一个组里面所有线程共享。
- Benchmark: 该状态在所有线程间共享。
JMH 陷阱
在使用 JMH 的过程中,一定要避免一些陷阱。
比如 JIT 优化中的死码消除,比如以下代码:
@Benchmark
public void testStringAdd(Blackhole blackhole) {
String a = "";
for (int i = 0; i < length; i++) {
a += i;
}
}JVM 可能会认为变量 a 从来没有使用过,从而进行优化把整个方法内部代码移除掉,这就会影响测试结果。
JMH 提供了两种方式避免这种问题,一种是将这个变量作为方法返回值 return a,一种是通过 Blackhole 的 consume 来避免 JIT 的优化消除。
JMH 可视化
除此以外,如果你想将测试结果以图表的形式可视化,可以试下这些网站:
比如将上面测试例子结果的 json 文件导入,就可以实现可视化: